🏠 Acceuil
Bienvenue - Welcome - مرحبا - dans la documentation NLP des langue tchadiennes
Toute la documentation des données est disponible sur le repository Corpus chadian languages.
Projet NLP Kalam-Na des langues tchadiennes
Vous pouvez apprendre davantage à travers ces slides sur les langues du Tchad. Nous le mettrons à jour en incluant les informations nécessaires sur la diversité linguistique du Tchad.
Le Tchad est un pays avec une large diversité linguistique et culturelle et compte 123 langues autochtones1. D’où l’urgence et la nécessité pour nous de développer des outils d’IA pour documenter, revitaliser et valoriser nos langues.
Toutes ces langues tchadiennes sont aujourd’hui invisibles dans l’univers numérique. Imaginez un instant qu’une personne souhaitant interagir en Zaghawa ou en Toupuri tente de converser avec un chatbot en ligne. À ce jour, une telle possibilité n’existe pas. Cette absence prive des millions de locuteurs d’un accès aux outils technologiques et freine l’inclusion linguistique dans l’intelligence artificielle (IA). Ce projet entend changer cette réalité.
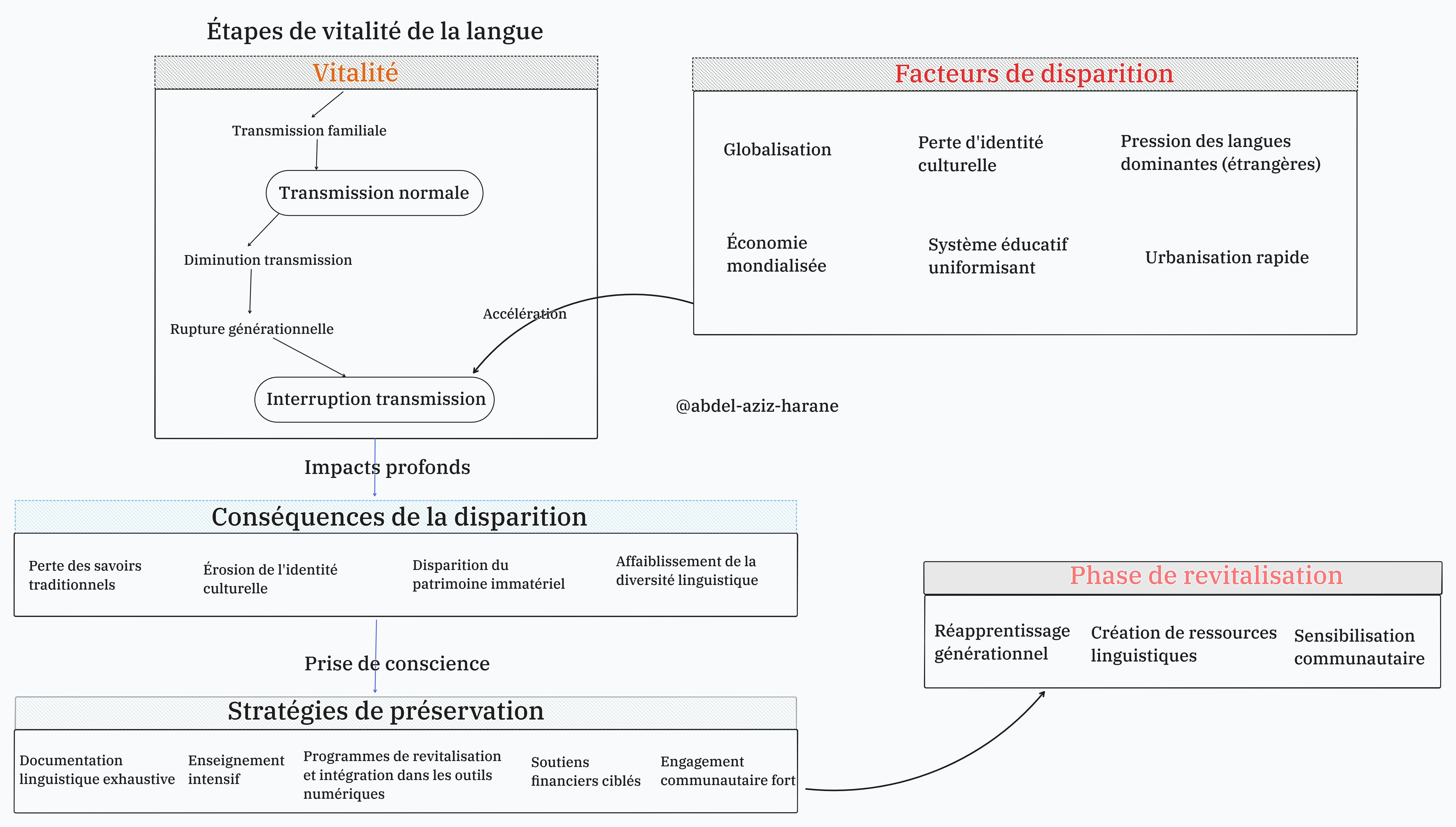
L’ambition est de concevoir des modèles avancés de traitement automatique du langage naturel (TALN/NLP – Natural Language Processing) capables de comprendre, générer et interagir en langues tchadiennes. En dotant ces langues de représentations numériques robustes, il devient possible de réduire la fracture technologique et de valoriser un patrimoine linguistique inestimable.
Le développement de Kalam-Na commence avec l’arabe tchadien (shu), avant d’être progressivement étendu à d’autres langues locales. Mais l’initiative ne s’arrête pas là. L’objectif à long terme est d’explorer des solutions multimodales (LLM) intégrant la reconnaissance vocale, la traduction automatique et d’autres applications de l’intelligence artificielle, afin d’offrir des outils véritablement adaptés aux besoins des communautés.
Anecdote d'une grand-mère :
« Mon petit-fils est allé à l’école et a appris à utiliser un ordinateur. Mais quand je lui ai demandé de me montrer comment discuter avec ces machines, il m’a dit que tout était en français ou en anglais. Alors Elle a répondu : Donc l’ordinateur ne parle pas ma langue ? »
Ce projet est non seulement une réponse à cette réalité mais nous voulons donner une voix numérique aux langues tchadiennes et permettre à tous d’interagir avec la technologie sans barrière linguistique.
Aujourd’hui, les langues tchadiennes souffrent d’un manque criant de données audio exploitables (voir la section à propos). Dans la phase de collecte des données audio et textuelles, ce projet vise à enregistrer et à annoter des heures de conversations – au moins 10 heures par langue – en capturant des histoires et poèmes traditionnels et des discours. Ces données serviront à développer des modèles avancés de synthèse vocale (Text-To-Speech, TTS) et de reconnaissance automatique de la parole (Automatic Speech Recognition, ASR).
Il est essentiel de ne plus se limiter au rôle de simples consommateurs des technologies d’IA. Rendre ces outils universels et inclusifs passe par l’intégration de nos langues, de nos voix et de notre patrimoine culturel dans l’écosystème numérique mondial.